SELECT (обучающий этап) задачи по SQL запросам 120 штук, DML 10 шт. Дистанционное обучение языку баз данных SQL. Интерактивные упражнения и тестирование по операторам SELECT,INSERT,UPDATE,DELETE языка SQL. SQL remote education. SQL statements exercises. Подзапросы, Соединение таблиц, Функции SQL, Введение в SQL, Скачать книги по SQL. Команды SQL,CREATE SEQUENCE,CREATE SYNONYM,CREATE USER,CREATE VIEW,Create Table,DROP,GRANT,INSERT,REVOKE,SET ROLE,SET TRANSACTION,SQL ALTER TABLE,SQL команды.
Стандарт SQL-92 специфицирует только функции, возвращающие системную дату/время. Например, функция CURRENT_TIMESTAMP возвращает сразу и дату, и время. Плюс имеются функции возвращающие что-либо одно.
Естественно, в силу такой ограниченности, реализации языка расширяют стандарт за счет добавления функций, облегчающий работу пользователей с данными этого типа. Здесь мы рассмотрим функции обработки даты/времени в T-SQL.
Функция DATEADD
СинтаксисDATEADD ( datepart , number, date )
Эта функция возвращает значение типа datetime, которое получается добавлением к дате date количества интервалов типа datepart, равного number. Например, мы можем к заданной дате добавить любое число лет, дней, часов, минут и т.д. Допустимые значения аргумента datepart приведены ниже и взяты из BOL.
Datepart
Допустимые сокращения
Year - год
yy, yyyy
Quarter - квартал
qq, q
Month - месяц
mm, m
Dayofyear - день года
dy, y
Day - день
dd, d
Week - неделя
wk, ww
Hour - час
hh
Minute - минута
mi, n
Second - секунда
ss, s
Millisecond - миллисекунда
ms
Пусть сегодня 23/01/2004, и мы хотим узнать, какой день будет через неделю. Мы можем написать
SELECT DATEADD(day, 7, current_timestamp)
а можем и так
SELECT DATEADD(ww, 1, current_timestamp)
В результате получим одно и то же; что-то типа 2004-01-30 19:40:58.923.
Однако мы не можем в этом случае написать
SELECT DATEADD(mm, 1/4, current_timestamp)
потому, что дробная часть значения аргумента datepart отбрасывается, и мы получим 0 вместо одной четвертой и, как следствие, текущий день.
Кроме того, мы можем использовать вместо CURRENT_TIMESTAMP функцию T-SQL GETDATE() с тем же самым эффектом. Наличие двух идентичных функций поддерживается, видимо, в ожидании последующего развития стандарта. Пример (схема 4). Определить, какой будет день через неделю после последнего полета.
SELECT DATEADD(day, 7, (SELECT MAX(date) max_date FROM pass_in_trip))
Использование подзапроса в качестве аргумента допустимо, т.к. этот подзапрос возвращает ЕДИНСТВЕННОЕ значение типа datetime.
Функция DATEDIFF
СинтаксисDATEDIFF ( datepart , startdate , enddate )
Функция возвращает интервал времени, прошедшего между двумя временными отметками - startdate (начальная отметка) и enddate (конечная отметка). Этот интервал может быть измерен в разных единицах. Возможные варианты определяются аргументом datepart и перечислены выше применительно к функции DATEADD. Пример (схема 4). Определить количество дней, прошедших между первым и последним совершенными рейсами.
SELECT DATEDIFF(dd, (SELECT MIN(date) FROM pass_in_trip), (SELECT MAX(date) FROM pass_in_trip))
Пример (схема 4). Определить продолжительность рейса 1123 в минутах.
Здесь следует принять во внимание, что время вылета (time_out) и время прилета (time_in) хранится в полях типа datetime таблицы Trip. Заметим, что SQL Server вплоть до версии 2000 не имеет отдельных темпоральных типов данных для даты и времени, появление которых ожидается в следующей версии (Yukon). Поэтому при вставке в поле datetime только времени (например, UPDATE trip SET time_out = '17:24:00' WHERE trip_no=1123), время будет дополнено значением даты по умолчанию ('1900-01-01').
Напрашивающееся решение
SELECT DATEDIFF(mi, time_out, time_in) dur FROM trip WHERE trip_no=1123,
(которое дает -760) будет неверным по двум причинам.
Во-первых, для рейсов, которые вылетают в один день, а прилетают на следующий, вычисленное таким способом значение будет неправильным. Во-вторых, ненадежно делать какие либо предположения относительно дня, который присутствует только в силу необходимости соответствовать типу datetime.
Но как определить, что самолет приземлился на следующий день? Тут помогает описание предметной области, где говорится, что полет не может продолжаться более суток. Итак, если время прилета не больше, чем время вылета, то этот факт имеет место. Теперь второй вопрос: как посчитать только время, с каким бы днем оно ни стояло?
Здесь может помочь функция T-SQL DATEPART.
Функция DATEPART
СинтаксисDATEPART ( datepart , date )
Эта функция возвращает целое число, представляющее собой указанную аргументом datepart часть заданной вторым аргументом даты (date).
Список допустимых значений аргумента datepart, описанный выше в данном разделе, дополняется еще одним значением
Datepart
Допустимые сокращения
Weekday - день недели
dw
Заметим, что возвращаемое функцией DATEPART значение в этом случае (номер дня недели) зависит от настроек, которые можно изменить с помощью оператора SET DATEFIRST, устанавливающего первый день недели. Для кого-то понедельник - день тяжелый, а для кого-то - воскресенье. Кстати, последнее значение принимается по умолчанию.
Однако вернемся к нашему примеру. В предположении, что время вылета/прилета является кратным минуте, мы можем его определить как сумму часов и минут. Поскольку функции даты/времени работают с целочисленными значениями, приведем результат к наименьшему интервалу - минутам. Итак, время вылета рейса 1123 в минутах
SELECT DATEPART(hh, time_out)*60 + DATEPART(mi, time_out) FROM trip WHERE trip_no=1123
и время прилета
SELECT DATEPART(hh, time_in)*60 + DATEPART(mi, time_in) FROM trip WHERE trip_no=1123
Теперь мы должны сравнить, превышает ли время прилета время вылета. Если это так, вычесть из первого второе, чтобы получить продолжительность рейса. В противном случае к разности нужно добавить одни сутки (24*60 = 1440 минут).
SELECT CASE WHEN time_dep>=time_arr THEN time_arr-time_dep+1440 ELSE time_arr-time_dep END dur FROM
( SELECT DATEPART(hh, time_out)*60 + DATEPART(mi, time_out) time_dep, DATEPART(hh, time_in)*60 + DATEPART(mi, time_in) time_arr FROM trip WHERE trip_no=1123
) tm
Здесь, чтобы не повторять длинные конструкции в операторе CASE, использован подзапрос. Конечно, результат получился достаточно громоздким, зато абсолютно корректным в свете сделанных к этой задаче замечаний. Пример (4 схема). Определить дату и время вылета рейса 1123.
В таблице совершенных рейсов Pass_in_trip содержится только дата рейса, но не время, т.к. в соответствии с предметной областью каждый рейс может выполняться только один раз в день. Для решения этой задачи нужно к дате, хранящейся в таблице Pass_in_trip, добавить время из таблицы Trip
SELECT pt.trip_no, DATEADD(mi, DATEPART(hh,time_out)*60 + DATEPART(mi,time_out), date) [time]
FROM pass_in_trip pt JOIN trip t ON pt.trip_no=t.trip_no WHERE t.trip_no=1123
Выполнив запрос, получим следующий результат
Trip_no
Time
1123
2003-04-05 16:20:00.000
1123
2003-04-08 16:20:00.000
DISTINCT необходим здесь, чтобы исключить возможные дубликаты, поскольку номер и дата рейса дублируются в этой таблице для каждого пассажира данного рейса.
Функция DATENAME
СинтаксисDATENAME ( datepart , date )
Эта функция возвращает символьное представление составляющей (datepart ) указанной даты (date). Аргумент, определяющий составляющую даты, может принимать одно из значений, перечисленных в вышеприведенной таблице.
Это дает нам простую возможность конкатенировать компоненты даты, получая любой нужный формат представления. Например, конструкция
Следует отметить, что данная функция выявляет отличие значений day и dayofyear аргумента datepart. Первый дает символьное представление дня указанной даты, в то время как второй дает символьное представление этого дня от начала года. Т.е.
SELECT DATENAME ( day , '2003-12-31' )
даст нам 31, а
SELECT DATENAME ( dayofyear , '2003-12-31' )
- 365.
В ряде случаев функцию DATEPART можно заменить более простыми функциями. Вот они: DAY ( date ) - целочисленное представление дня указанной даты. Эта функция эквивалентна функции DATEPART(dd, date). MONTH ( date ) - целочисленное представление месяца указанной даты. Эта функция эквивалентна функции DATEPART(mm, date). YEAR ( date ) - целочисленное представление года указанной даты. Эта функция эквивалентна функции DATEPART(yy, date).
Функция @@DATEFIRST
@@DATEFIRST возвращает число, которое определяет первый день недели, установленный для текущей сессии. При этом 1 соответствует понедельнику, а 7, соответственно, воскресенью. Т.е. если
SELECT @@DATEFIRST;
возвращает 7, то первым днем недели считается воскресенье (соответствует текущим настройкам на сайте).Рекомендуемые упражнения: 78, 110.
В реализациях языка SQL может быть выполнено неявное преобразование типов. Так, например, в T-SQL при сравнении или комбинировании значений типов smallint и int, данные типа smallint неявно преобразуются к типу int. Подробно о явном и неявном преобразовании типов в MS SQL Server можно прочитать в BOL. Пример. Вывести среднюю цену ПК-блокнотов с предваряющим текстом "средняя цена = ".
Попытка выполнить запрос
SELECT 'Средняя цена = ' + AVG(price) FROM laptop;
приведет к сообщению об ошибке
Implicit conversion from data type varchar to money is not allowed. Use the CONVERT function to run this query.
Это сообщение означает, что система не может выполнить неявное преобразование типа varchar к типу money. В подобных ситуациях может помочь явное преобразование типов. При этом, как указано в сообщении об ошибке, можно воспользоваться функцией CONVERT. Однако эта функция не стандартизована, поэтому в целях переносимости рекомендуется использовать стандартное выражение CAST. С него и начнем.
Если переписать наш запрос в виде
SELECT 'Средняя цена = ' + CAST(AVG(price) AS CHAR(15)) FROM laptop;
в результате получим то, что требовалось:
Средняя цена = 1410.44
Мы использовали выражение явного преобразования типов CAST для приведения среднего значения цены к строковому представлению. Синтаксис выражения CAST очень простой:CAST(<выражение> AS <тип данных>)
При этом следует иметь в виду, во-первых, что не любые преобразования типов возможны (стандарт содержит таблицу допустимых преобразований типов данных). Во-вторых, результат функции CAST для значения выражения, равного NULL, тоже будет NULL.
Рассмотрим еще один пример: определить средний год спуска на воду кораблей из таблицы Ships. Запрос
SELECT AVG(launched) FROM ships;
даст результат 1926. В принципе все правильно, т.к. мы получили в результате то, что просили - ГОД. Однако среднее арифметическое будет составлять примерно 1926,2381. Тут следует отметить, что агрегатные функции (за исключением функции COUNT, которая всегда возвращает целое число) наследуют тип данных обрабатываемых значений. Поскольку поле launched - целочисленное, мы и получили среднее значение с отброшенной дробной частью (заметьте - не округленное).
А если нас интересует результат с заданной точностью, скажем, до двух десятичных знаков? Применение выражения CAST к среднему значению ничего не даст по указанной выше причине. Действительно,
SELECT CAST(AVG(launched) AS NUMERIC(6,2)) FROM ships;
вернет значение 1926.00. Следовательно, CAST нужно применить к аргументу агрегатной функции:
SELECT AVG(CAST(launched AS NUMERIC(6,2))) FROM ships;
Результат - 1926.238095. Опять не то. Причина состоит в том, что при вычислении среднего значения было выполнено неявное преобразование типа. Сделаем еще один шаг:
SELECT CAST(AVG(CAST(launched AS NUMERIC(6,2))) AS NUMERIC(6,2)) FROM ships;
В результате получим то, что нужно - 1926.24. Однако это решение выглядит очень громоздко. Заставим неявное преобразование типа поработать на нас:
SELECT CAST(AVG(launched*1.0) AS NUMERIC(6,2)) FROM ships;
Т.е. мы использовали неявное преобразование целочисленного аргумента к точному числовому типу (EXACT NUMERIC), умножив его на вещественную единицу, после чего применили явное приведения типа результата агрегатной функции.
Аналогичные преобразования типа можно выполнить с помощью функции CONVERT:
SELECT CONVERT(NUMERIC(6,2),AVG(launched*1.0)) FROM ships;
Функция CONVERT имеет следующий синтаксис:
CONVERT (<тип данных>[(<длина>)], <выражение> [, <стиль>])
Основное отличие функции CONVERT от функции CAST состоит в том, что первая позволяет форматировать данные (например, темпоральные данные типа datetime) при преобразовании их к символьному типу и указывать формат при обратном преобразовании. Разные целочисленные значения необязательного аргумента стиль соответствуют определенным форматам. Рассмотрим следующий пример
Здесь мы преобразуем строковое представление даты к типу datetime, после чего выполняем обратное преобразование, чтобы продемонстрировать результат форматирования. Поскольку значение аргумента стиль не задано, используется значение по умолчанию (0 или 100). В результате получим
Jul 22 2003 12:00AM
Ниже приведены некоторые другие значения аргумента стиль и результат, полученный на приведенном выше примере. Заметим, что значения стиль большие 100 приводят к четырехзначному отображению года.
стиль
формат
1
07/22/03
11
03/07/22
3
22/07/03
121
2003-07-22 00:00:00.000
Перечень всех возможных значений аргумента стиль можно посмотреть в BOL.
Оператор CASE
Пусть требуется вывести список всех моделей ПК с указанием их цены. При этом если модель отсутствует в продаже (нет в таблице РС), то вместо цены вывести текст: "Нет в наличии".
Список всех моделей ПК с ценами можно получить с помощью запроса:
SELECT DISTINCT product.model, price FROM product LEFT JOIN pc c
ON product.model=c.model
WHERE product.type='pc';
В результирующем наборе отсутствующая цена будет заменена NULL-значением:
model
price
1121
850
1232
350
1232
400
1232
600
1233
600
1233
950
1233
980
1260
350
2111
NULL
2112
NULL
Чтобы заменить NULL-значения нужным текстом, можно воспользоваться оператором CASE:
SELECT DISTINCT product.model,
CASE WHEN price IS NULL THEN 'Нет в наличии' ELSE CAST(price AS CHAR(20)) END price
FROM product LEFT JOIN pc c ON product.model=c.model
WHERE product.type='pc'
Оператор CASE в зависимости от указанных условий возвращает одно из множества возможных значений. В нашем примере условием является проверка на NULL. Если это условие выполняется, то возвращается текст "Нет в наличии", в противном случае (ELSE) возвращается значение цены. Здесь есть один принципиальный момент. Поскольку результатом оператора SELECT всегда является таблица, то все значения любого столбца должны иметь один и тот же тип данных (с учетом неявного приведения типов). Поэтому мы не можем наряду с ценой (числовой тип) выводить символьную константу. Вот почему к полю price применяется преобразование типов, чтобы привести его значения к символьному представлению. В результате получим
model
price
1121
850
1232
350
1232
400
1232
600
1233
600
1233
950
1233
980
1260
350
2111
Нет в наличии
2112
Нет в наличии
Оператор CASE может быть использован в одной из двух синтаксических форм записи: 1-я форма
CASE <проверяемое выражение>
WHEN <сравниваемое выражение 1>
THEN <возвращаемое значение 1>
…
WHEN <сравниваемое выражение N>
THEN <возвращаемое значение N>
[ELSE <возвращаемое значение>]
END
2-я форма
CASE
WHEN <предикат 1>
THEN <возвращаемое значение 1>
…
WHEN <предикат N>
THEN <возвращаемое значение N>
[ELSE <возвращаемое значение>]
END
Все предложения WHEN должны иметь одинаковую синтаксическую форму, т.е. нельзя смешивать первую и вторую формы. При использовании первой синтаксической формы условие WHEN удовлетворяется, как только значение проверяемого выражения станет равным значению выражения, указанного в предложении WHEN. При использовании второй синтаксической формы условие WHEN удовлетворяется, как только предикат принимает значение TRUE. При удовлетворении условия оператор CASE возвращает значение, указанное в соответствующем предложении THEN. Если ни одно из условий WHEN не выполнилось, то будет использовано значение, указанное в предложении ELSE. При отсутствии ELSE, будет возвращено NULL-значение. Если удовлетворены несколько условий, то будет возвращено значение предложения THEN первого из них.
В приведенном выше примере была использована вторая форма оператора CASE.
Заметим, что для проверки на NULL стандарт предлагает более короткую форму оператора - COALESCE. Этот оператор имеет произвольное число параметров и возвращает значение первого, отличного от NULL. Для двух параметров оператор COALESCE(A, B) эквивалентен следующему оператору CASE:
CASE WHEN A IS NOT NULL THEN A ELSE B END
Решение рассмотренного выше примера при использовании оператора COALESCE можно переписать следующим образом:
SELECT DISTINCT product.model,
COALESCE(CAST(price as CHAR(20)),'Нет в наличии') price
FROM product LEFT JOIN pc c ON product.model=c.model
WHERE product.type='pc';
Использование первой синтаксической формы оператора CASE можно продемонстрировать на следующем примере: Вывести все имеющиеся модели ПК с указанием цены. Отметить самые дорогие и самые дешевые модели.
SELECT DISTINCT model, price,
CASE price WHEN (SELECT MAX(price) FROM pc) THEN 'Самый дорогой'
WHEN (SELECT MIN(price) FROM pc) THEN 'Самый дешевый'
ELSE 'Средняя цена' END comment
FROM pc ORDER BY price;
Вот полный перечень функций работы со строками, взятый из BOL:
ASCII
NCHAR
SOUNDEX
CHAR
PATINDEX
SPACE
CHARINDEX
REPLACE
STR
DIFFERENCE
QUOTENAME
STUFF
LEFT
REPLICATE
SUBSTRING
LEN
REVERSE
UNICODE
LOWER
RIGHT
UPPER
LTRIM
RTRIM
Начнем с двух взаимно обратных функций - ASCII и CHAR.
Функция ASCII возвращает ASCII-код крайнего левого символа строкового выражения, являющегося аргументом функции.
Вот, например, как можно определить, сколько имеется разных букв, с которых начинаются названия кораблей в таблице Ships:
SELECT COUNT(DISTINCT ASCII(name)) FROM Ships
Результат - 11. Чтобы выяснить, какие это буквы, мы можем применить функцию CHAR, которая возвращает символ по известному ASCII-коду (от 0 до 255):
SELECT DISTINCT CHAR(ASCII(name)) FROM Ships ORDER BY 1
Следует отметить, что аналогичный результат можно получить проще с помощью еще одной функции - LEFT, которая имеет следующий синтаксис: LEFT (<строковое выражение>, <целочисленное выражение> )
и вырезает заданное вторым аргументом число символов слева из строки, являющейся первым аргументом. Итак,
SELECT DISTINCT LEFT(name, 1) FROM Ships ORDER BY 1
А вот как, например, можно получить таблицу кодов всех алфавитных символов:
SELECT CHAR(ASCII('a')+ num-1) letter, ASCII('a')+ num - 1 [code]
FROM (SELECT 5*5*(a-1)+5*(b-1) + c AS num
FROM (SELECT 1 a UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) x
CROSS JOIN
(SELECT 1 b UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) y
CROSS JOIN
(SELECT 1 c UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) z
) x
WHERE ASCII('a')+ num -1 BETWEEN ASCII('a') AND ASCII('z')
Тех, кто еще не в курсе генерации числовой последовательности, отсылаю к соответствующей .
Как известно, коды строчных и прописных букв отличаются. Поэтому чтобы получить полный набор без переписывания запроса, достаточно просто дописать к вышеприведенному коду аналогичный:
UNION
SELECT CHAR(ASCII('A')+ num-1) letter, ASCII('A')+ num - 1 [code]
FROM (SELECT 5*5*(a-1)+5*(b-1) + c AS num
FROM (SELECT 1 a UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) x
CROSS JOIN
(SELECT 1 b UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) y
CROSS JOIN
(SELECT 1 c UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) z
) x
WHERE ASCII('A')+ num -1 BETWEEN ASCII('A') AND ASCII('Z')
Чтобы таблица выглядела более патриотично, достаточно заменить латинские буквы "a" и "A" на неотличимые на взгляд русские - "а" и "А", а "z" и "Z" на "я" и "Я". Вот только буквы "ё" вы не увидите в этой таблице, т.к. в кодовой таблице ASCII эти символы лежат отдельно, что легко проверить:
SELECT ASCII('ё') UNION ALL SELECT ASCII('Ё')
Я полагаю, что не будет сложным добавить эту букву в таблицу, если потребуется.
Рассмотрим теперь задачу определения нахождения искомой подстроки в строковом выражении. Для этого могут использоваться две функции - CHARINDEX и PATINDEX. Обе они возвращают начальную позицию (позицию первого символа подстроки) подстроки в строке. Функция CHARINDEX имеет синтаксис: CHARINDEX (искомое_выражение, строковое_выражение[, стартовая_позиция])
Здесь необязательный целочисленный параметр стартовая_позиция определяет позицию в строковом выражении, начиная с которой выполняется поиск искомого_выражения . Если этот параметр опущен, поиск выполняется от начала строкового_выражения. Например, запрос
SELECT name FROM Ships WHERE CHARINDEX('sh', name) > 0
будет выводить те корабли, в которых имеется сочетание символов "sh". Здесь используется тот факт, что если искомая строка не будет обнаружена, то функция CHARINDEX возвращает 0. Результат выполнения запроса будет содержать следующие корабли:
name
Kirishima
Musashi
Washington
Следует отметить, что если искомая подстрока либо строковое выражение есть NULL, то результатом функции тоже будет NULL.
Следующий пример определяет позиции первого и второго вхождения символа "a" в имени корабля "California"
SELECT CHARINDEX('a',name) first_a,
CHARINDEX('a', name, CHARINDEX('a', name)+1) second_a
FROM Ships WHERE name='California'
Обратите внимание, что при определении второго символа в функции используется стартовая позиция, которой является позиция следующего за первой буквой "a" символа - CHARINDEX('a', name)+1. Правильность результата - 2 и 10 - легко проверить :-).
Функция PATINDEX имеет синтаксис: PATINDEX ('%образец%' , строковое_выражение)
Главное отличие этой функции от CHARINDEX заключается в том, что поисковая строка может содержать подстановочные знаки - % и _. При этом концевые знаки "%" являются обязательными. Например, использование этой функции в первом примере будет иметь вид
SELECT name FROM Ships WHERE PATINDEX('%sh%', name) > 0
А вот, например, как можно найти имена кораблей, которые содержат последовательность из трех символов, первый и последний из которых есть "e":
SELECT name FROM Ships WHERE PATINDEX('%e_e%', name) >0
Результат выполнения этого запроса выглядит следующим образом:
name
Revenge
Royal Sovereign
Парная к LEFT функция RIGHT возвращает заданное число символов справа из строкового выражения: RIGHT(<строковое выражения>,<число символов>)
Вот, например, как можно определить имена кораблей, которые начинаются и заканчиваются на одну и ту же букву:
SELECT name FROM Ships WHERE LEFT(name, 1) = RIGHT(name, 1)
То, что в результате мы получим пустой результирующий набор, означает, что таких кораблей в базе данных нет. Давайте возьмем комбинацию значений - класс и имя корабля.
Соединение двух строковых значений в одно называется конкатенацией, и в SQL Server для этой операции используется знак "+" (в стандарте "||"). Итак,
SELECT * FROM (
SELECT class +' '+ name AS cn FROM Ships
) x
WHERE LEFT(cn, 1)=RIGHT(cn, 1)
Здесь мы разделяем пробелом имя класса и имя корабля. Кроме того, чтобы не повторять всю конструкцию в качестве аргумента функции, используем подзапрос. Результат будет иметь вид:
cn
Iowa Missouri
North Carolina Washington
А если строковое выражение будет содержать лишь одну букву? Запрос выведет ее. В этом легко убедиться, написав
SELECT * FROM (
SELECT class +' '+ name AS cn FROM Ships
UNION ALL
SELECT 'a' as nc
) x
WHERE LEFT(cn, 1)=RIGHT(cn, 1)
Чтобы исключить этот случай, можно воспользоваться еще одной полезной функцией LEN (<строковое выражение>), которая возвращает число символов в строке. Ограничимся случаем, когда число символов больше единицы:
SELECT * FROM (
SELECT class +' '+ name AS cn FROM Ships
UNION ALL
SELECT 'a' as nc
) x
WHERE LEFT(cn, 1)=RIGHT(cn, 1) AND LEN(cn)>1
Замечание. Реализация этой функции в MS SQL Server имеет одну особенность, а именно, при подсчете длины не учитываются концевые пробелы.
Действительно, выполним следующий код:
Функция REPLICATE дополняет константу 'abcde' пятью пробелами справа, которые не учитываются функцией LEN, - в обоих случаях получаем 5.
Функция DATALENGTH возвращает число байтов в представлении переменной и демонстрирует нам различие между типами CHAR и VARCHAR. DATALENGTH даст нам 12 для типа CHAR и 10 - для VARCHAR.
Как и следовало ожидать, DATALENGTH для переменной типа VARCHAR вернула фактическую длину переменной. Но почему для переменной типа CHAR результат оказался равным 12? Дело в том, что CHAR - это тип фиксированной длины. Если значение переменной оказывается меньше ее длины, а длину мы объявили как CHAR(12), то значение переменной будет "выровнено" до требуемой длины за счет добавления концевых пробелов.
На сайте имеются задачи, в которых требуется упорядочить (найти максимум и т.д.) в числовом порядке значения, представленные в текстовом формате. Например, номер места в самолете ("2d") или скорость CD ("24x"). Проблема заключается в том, что текст сортируется так (по возрастанию)
11a
1a
2a
Действительно,
SELECT '1a' AS place
UNION ALL SELECT '2a'
UNION ALL SELECT '11a'
ORDER BY 1
Если же требуется упорядочить места в порядке возрастания рядов, то порядок должен быть такой
1a
2a
11a
Чтобы добиться такого порядка, нужно выполнить сортировку по числовым значениям, присутствующим в тексте. Можно предложить такой алгоритм:
1. Извлечь число из строки.
2. Привести его к числовому формату.
3. Выполнить сортировку по приведенному значению.
Т.к. нам известно, что буква только одна, то для извлечения числа из строки можно воспользоваться следующей конструкцией, которая не зависит от числа цифр в номере места:
LEFT(place, LEN(place)-1)
Если только этим и ограничиться, то получим
place
1a
11a
2a
Приведение к числовому формату может быть следующим:
CAST (LEFT(place, LEN(place)-1) AS INT)
Осталось выполнить сортировку
SELECT * FROM (
SELECT '1a' AS place
UNION ALL SELECT '2a'
UNION ALL SELECT '11a'
) x
ORDER BY CAST(LEFT(place, LEN(place)-1) AS INT)
Что и требовалось доказать.
Ранее мы для извлечения числа из текстовой строки пользовались функцией LEFT, т.к. нам было известно априори, какое число символов нужно убрать справа (один). А если же нужно извлечь строку из подстроки не по известной позиции символа, а по самому символу? Например: извлечь все символы до первой буквы "х" (значение скорости CD).
В этом случае мы можем использовать также уже рассмотренную ранее функцию CHARINDEX, которая позволит определить неизвестную позицию символа:
SELECT model, LEFT(cd, CHARINDEX('x', cd) -1) FROM PC
Функция SUBSTRING
SUBSTRING (<выражение>, <начальная позиция>, <длина> )
Эта функция позволяет извлечь из выражения его часть заданной длины, начиная от заданной начальной позиции. Выражение может быть символьной или бинарной строкой, а также иметь тип text или image. Например, если нам потребуется получить 3 символа в названии корабля, начиная со 2-го символа, то сделать без помощи функции SUBSTRING будет не так просто. А так мы пишем:
SELECT name, SUBSTRING(name, 2, 3) FROM Ships
В случае, когда нужно извлечь все символы, начиная с некоторого, мы также можем использовать эту функцию. Например,
SELECT name, SUBSTRING(name, 2, LEN(name)) FROM Ships
даст нам все символы в названиях кораблей от второй буквы в имени. Обратите внимание на то, что для указания числа извлекаемых символов я использовал функцию LEN(name), которая возвращает число символов в имени. Понятно, что поскольку мне нужны символы, начиная со второго, то их число будет меньше общего количества символов в имени. Однако это не вызывает ошибки, поскольку если указанное число символов превышает возможное число, то будут извлечены все символы до конца строки. Поэтому я и беру их с запасом, не утруждая себя вычислениями.
Функция REVERSE
Эта функция переворачивает строку, как бы читая ее справа налево. Т.е. результатом запроса
SELECT REVERSE('abcdef')
будет 'fedcba'. Если бы в языке отсутствовала функция RIGHT, то запрос
SELECT RIGHT('abcdef',3)
можно было бы равносильно заменить запросом
SELECT REVERSE(LEFT(REVERSE('abcdef'),3))
Я вижу пользу этой функции в следующем. Пусть нам требуется определить позицию не первого, а последнего вхождения некоторого символа (или последовательности символов) в строке. Вспомним пример, в котором мы определяли позицию первого символа "а" в названии корабля "California":
SELECT CHARINDEX('a', name) first_a
FROM Ships WHERE name='California'
Определим теперь позицию последнего вхождения в это название символа "а". Функция
CHARINDEX('a', REVERSE(name))
позволит найти эту позицию, но справа. Для получения позиции этого же символа слева достаточно написать
SELECT LEN(name) + 1 - CHARINDEX('a', REVERSE(name)) first_a
FROM Ships WHERE name='California'
Функция REPLACE
REPLACE ( <строка1> , <строка2> , <строка3> )
Заменяет в строке1 все вхождения строки2 на строку3. Эта функция, безусловно, полезна в операторах обновления (UPDATE), если нужно изменить (исправить) содержимое столбца. Пусть, например, нужно заменить все пробелы дефисом в названиях кораблей. Тогда можно написать
UPDATE Ships
SET name = REPLACE(name, ' ', '-')
(Этот пример можно выполнить на странице с упражнениями DML, где разрешаются запросы на изменение данных)
Однако эта функция может найти применение и в более нетривиальных случаях. Давайте определим, сколько раз в названии корабля используется буква "a". Идея проста: заменим каждую искомую букву двумя любыми символами, после чего посчитаем разность длин полученной и искомой строки. Итак,
SELECT name, LEN(REPLACE(name, 'a', 'aa')) - LEN(name) FROM Ships
А если нам нужно определить число вхождений произвольной последовательности символов, скажем, передаваемой в качестве параметра в хранимую процедуру? Использованный выше алгоритм в этом случае следует дополнить делением на число символов в искомой последовательности:
DECLARE @str AS VARCHAR(100)
SET @str='ma'
SELECT name, (LEN(REPLACE(name, @str, @str + @str)) - LEN(name))/LEN(@str) FROM Ships
Для удвоения числа искомых символов здесь применялась конкатенация - @str + @str . Однако для этой цели можно использовать еще одну функцию - REPLICATE, которая повторяет первый аргумент такое число раз, которое задается вторым аргументом.
SELECT name, (LEN(REPLACE(name, @str, REPLICATE(@str, 2))) - LEN(name))/LEN(@str) FROM Ships
Т.е. мы повторяем дважды подстроку, хранящуюся в переменной @str .
Если же нужно заменить в строке не определенную последовательность символов, а заданное число символов, начиная с некоторой позиции, то проще использовать функцию STUFF: STUFF (<строка1> , <стартовая позиция> , <L> , <строка2>)
Эта функция заменяет подстроку длиной L, которая начинается со стартовой позиции в строке1, на строку2. Пример. Изменить имя корабля: оставив в его имени 5 первых символов, дописать "_" (нижнее подчеркивание) и год спуска на воду. Если в имени менее 5 символов, дополнить его пробелами.
Можно решать эту задачу с помощью разных функций. Мы же попытаемся это сделать с помощью функции STUFF. В первом приближении напишем (ограничимся запросом на выборку):
SELECT name, STUFF(name, 6, LEN(name), '_'+launched) FROM Ships
Третьим аргументом (количество символов для замены) я использую LEN(name), т.к. мне нужно заменить все символы до конца строки, поэтому я беру с запасом - исходное число символов в имени. И все же этот запрос вернет ошибку. Причем дело не в третьем аргументе, а в четвертом, где выполняется конкатенация строковой константы и числового столбца. Ошибка приведения типа. Для преобразования числа к его строковому представлению можно воспользоваться еще одной встроенной функцией - STR: STR ( <число с плавающей точкой> [ , <длина> [ , <число десятичных знаков> ] ] )
При этом преобразовании выполняется округление, а длина задает длину результирующей строки. Например,
STR(3.3456, 5, 1)
3.3
STR(3.3456, 5, 2)
3.35
STR(3.3456, 5, 3)
3.346
STR(3.3456, 5, 4)
3.346
Обратите внимание, что если полученное строковое представление числа меньше заданной длины, то добавляются лидирующие пробелы. Если же результат больше заданной длины, то усекается дробная часть (с округлением); в случае же целого числа получаем соответствующее число звездочек "*":
STR(12345,4,0)
****
Кстати, по умолчанию используется длина в 10 символов. Имея в виду, что год представлен четырьмя цифрами, напишем
SELECT name, STUFF(name, 6, LEN(name), '_'+STR(launched, 4)) FROM Ships
Уже почти все правильно. Осталось учесть случай, когда число символов в имени менее 6, т.к. в этом случае функция STUFF дает NULL. Ну что ж вытерпим до конца мучения, связанные с использованием этой функции в данном примере, попутно применив еще одну строковую функцию. Добавим конечные пробелы, чтобы длина имени была заведомо больше 6. Для этого имеется специальная функция SPACE SPACE(<число пробелов>):
SELECT name, STUFF(name + SPACE(6), 6, LEN(name), '_'+STR(launched,4)) FROM Ships
Функции LTRIM и RTRIM
LTRIM (<строковое выражение>) RTRIM (<строковое выражение>)
отсекают соответственно лидирующие и конечные пробелы строкового выражения, которое неявно приводится к типу VARCHAR.
Пусть требуется построить такую строку: имя пассажира_идентификатор пассажира для каждой записи из таблицы Passenger. Если мы напишем
SELECT name + '_' + CAST(id_psg AS VARCHAR) FROM Passenger,
то в результате получим что-то типа:
A _1
Это связано с тем, что столбец name имеет тип CHAR(30). Для этого типа короткая строка дополняется пробелами до заданного размера (у нас 30 символов). Здесь нам как раз и поможет функция RTRIM:
SELECT RTRIM(name) + '_' + CAST(id_psg AS VARCHAR) FROM Passenger
Функции LOWER и UPPER
LOWER(<строковое выражение>) UPPER(<строковое выражение>)
преобразуют все символы аргумента соответственно к нижнему и верхнему регистру. Эти функции оказываются полезными при сравнении регистрозависимых строк.
Пара интересных функций SOUNDEX и DIFFERENCE: SOUNDEX(<строковое выражение>) DIFFERENCE (<строковое выражение_1>, <строковое выражение_2>)
Позволяют определить близость звучания слов. При этом SOUNDEX возвращает четырехсимвольный код, используемый для сравнения, а DIFFERENCE собственно и оценивает близость звучания двух сравниваемых строковых выражений. Поскольку эти функции не поддерживают кириллицы, отсылаю интересующихся к BOL за примерами их использования.
В заключение приведем функции и несколько примеров использования юникода.
Функция UNICODE
UNICODE (<строковое выражение>)
возвращает юникод первого символа строкового выражения.
Функция NCHAR
NCHAR (<целое>)
возвращает символ по его юникоду. Несколько примеров.
SELECT ASCII('а'), UNICODE('а')
возвращает код ASCII и юникод русской буквы "а": 224 и 1072.
SELECT CHAR(ASCII('а')), CHAR(UNICODE('а'))
Пытаемся восстановить символ по его коду. Получаем "а" и NULL. NULL-значение возвращается потому, что кода 1072 нет в обычной кодовой таблице.
SELECT CHAR(ASCII('а')), NCHAR(UNICODE('а'))
Теперь все нормально, в обоих случаях "а". Наконец,
SELECT NCHAR(ASCII('а'))
даст "a", т.к. юникод 224 соответствует именно этой букве.
Приведенные здесь примеры можно выполнить непосредственно на сайте, установив флажок "Без проверки" на странице с упражнениями на SELECT.
Язык манипуляции данными (DML - Data Manipulation Language) помимо оператора SELECT, осуществляющего извлечение информации из базы данных, включает операторы, изменяющие состояние данных. Этими операторами являются:
INSERT
Добавление записей (строк) в таблицу БД
UPDATE
Обновление данных в столбце таблицы БД
DELETE
Удаление записей из таблицы БД
Оператор INSERT
Оператор INSERT вставляет новые строки в таблицу. При этом значения столбцов могут представлять собой литеральные константы либо являться результатом выполнения подзапроса. В первом случае для вставки каждой строки используется отдельный оператор INSERT; во втором случае будет вставлено столько строк, сколько возвращается подзапросом.
Синтаксис оператора
INSERT INTO <имя таблицы>[(<имя столбца>,...)]
{VALUES (< значение столбца>,…)}
| <выражение запроса>
| {DEFAULT VALUES};
Как видно из представленного синтаксиса, список столбцов не является обязательным. В том случае, если он отсутствует, список вставляемых значений должен быть полный, т.е. обеспечивать значения для всех столбцов таблицы. При этом порядок значений должен соответствовать порядку столбцов, заданному оператором CREATE TABLE для таблицы, в которую вставляются строки. Кроме того, каждое из этих значений должно быть того же типа (или приводиться к нему), что и тип, определенный для соответствующего столбца в операторе CREATE TABLE. В качестве примера рассмотрим вставку строки в таблицу Product, созданную следующим оператором CREATE TABLE:
CREATE TABLE [dbo].[product] (
[maker] [char] (1) NOT NULL ,
[model] [varchar] (4) NOT NULL ,
[type] [varchar] (7) NOT NULL )
Пусть требуется добавить в эту таблицу модель ПК 1157 производителя B. Это можно сделать следующим оператором:
INSERT INTO Product VALUES ('B', 1157, 'PC');
Если задать список столбцов, то можно изменить "естественный" порядок их следования:
INSERT INTO Product (type, model, maker) VALUES ('PC', 1157, 'B');
Казалось бы, это совершенно излишняя возможность, которая делает конструкцию только более громоздкой. Однако она становится выигрышной, если столбцы имеют значения по умолчанию. Рассмотрим следующую структуру таблицы:
Отметим, что здесь значения всех столбцов имеют значения по умолчанию (первые два - NULL, а последний столбец - type - 'PC'). Теперь мы могли бы написать:
INSERT INTO Product_D (model, maker) VALUES (1157, 'B');
В этом случае отсутствующее значение при вставке строки будет заменено значением по умолчанию - 'PC'. Заметим, что если для столбца в операторе CREATE TABLE не указано значение по умолчанию и не указано ограничение NOT NULL, запрещающее использование NULL в данном столбце таблицы, то подразумевается значение по умолчанию NULL.
Возникает вопрос: а можно ли не указывать список столбцов и, тем не менее, воспользоваться значениями по умолчанию? Ответ положительный. Для этого нужно вместо явного указания значения использовать зарезервированное слово DEFAULT:
INSERT INTO Product_D VALUES ('B', 1158, DEFAULT);
Поскольку все столбцы имеют значения по умолчанию, для вставки строки со значениями по умолчанию можно было бы написать:
INSERT INTO Product_D VALUES (DEFAULT, DEFAULT, DEFAULT);
Однако для этого случая предназначена специальная конструкция DEFAULT VALUES (смотри синтаксис оператора), с помощью которой вышеприведенный оператор можно переписать в виде
INSERT INTO Product_D DEFAULT VALUES;
Заметим, что при вставке строки в таблицу проверяются все ограничения, наложенные на данную таблицу. Это могут быть ограничения первичного ключа или уникального индекса, проверочные ограничения типа CHECK, ограничения ссылочной целостности. В случае нарушения какого-либо ограничения вставка строки будет отвергнута.
Рассмотрим теперь случай использования подзапроса. Пусть нам требуется вставить в таблицу Product_D все строки из таблицы Product, относящиеся к моделям персональных компьютеров (type = 'PC'). Поскольку необходимые нам значения уже имеются в некоторой таблице, то формирование вставляемых строк вручную, во-первых, является неэффективным, а, во-вторых, может допускать ошибки ввода. Использование подзапроса решает эти проблемы:
INSERT INTO Product_D SELECT * FROM Product WHERE type = 'PC';
Использование в подзапросе символа "*" является в данном случае оправданным, т.к. порядок следования столбцов является одинаковым для обеих таблиц. Если бы это было не так, следовало бы использовать список столбцов либо в операторе INSERT, либо в подзапросе, либо в обоих местах, который приводил бы в соответствие порядок следования столбцов:
INSERT INTO Product_D(maker, model, type)
SELECT * FROM Product WHERE type = 'PC';
или
INSERT INTO Product_D
SELECT maker, model, type FROM Product WHERE type = 'PC';
или
INSERT INTO Product_D(maker, model, type)
SELECT maker, model, type FROM Product WHERE type = 'PC';
Здесь, также как и ранее, можно указывать не все столбцы, если требуется использовать имеющиеся значения по умолчанию, например:
INSERT INTO Product_D (maker, model)
SELECT maker, model FROM Product WHERE type = 'PC';
В данном случае в столбец type таблицы Product_D будет подставлено значение по умолчанию 'PC' для всех вставляемых строк.
Отметим, что при использовании подзапроса, содержащего предикат, будут вставлены только те строки, для которых значение предиката равно TRUE (не UNKNOWN!). Другими словами, если бы столбец type в таблице Product допускал бы NULL-значение, и это значение присутствовало бы в ряде строк, то эти строки не были бы вставлены в таблицу Product_D.
Преодолеть ограничение на вставку одной строки в операторе INSERT при использовании VALUES позволяет искусственный прием использования подзапроса, формирующего строку с предложением UNION ALL. Так если нам требуется вставить несколько строк при помощи одного оператора INSERT, можно написать:
INSERT INTO Product_D
SELECT 'B' AS maker, 1158 AS model, 'PC' AS type
UNION ALL
SELECT 'C', 2190, 'Laptop'
UNION ALL
SELECT 'D', 3219, 'Printer';
Использование UNION ALL предпочтительней UNION даже, если гарантировано отсутствие строк-дубликатов, т.к. в этом случае не будет выполняться проверка для исключения дубликатов.
Вставка строк в таблицу, содержащую автоинкрементируемое поле
Многие коммерческие продукты допускают использование автоинкрементируемых столбцов в таблицах, т.е. полей, значение которых формируется автоматически при добавлении новых записей. Такие столбцы широко используются в качестве первичных ключей таблицы, т.к. они автоматически обеспечивают уникальность. Типичным примером столбца такого типа является последовательный счетчик, который при вставке строки генерирует значение на единицу большее предыдущего значения (значения, полученного при вставке предыдущей строки).
Ниже приводится пример создания таблицы с автоинкрементируемым столбцом (code) в MS SQL Server.
CREATE TABLE [Printer_Inc] (
[code] [int] IDENTITY(1,1) PRIMARY KEY ,
[model] [varchar] (4) NOT NULL ,
[color] [char] (1) NOT NULL ,
[type] [varchar] (6) NOT NULL ,
[price] [float] NOT NULL )
Автоинкрементируемое поле определяется посредством конструкции IDENTITY (1, 1). При этом первый параметр свойства IDENTITY (1) определяет, с какого значения начнется отсчет, а второй - какой шаг будет использоваться для приращения значения. Таким образом, в нашем примере первая вставленная запись будет иметь в столбце code значение 1, вторая - 2 и т.д.
Поскольку в поле code значение формируется автоматически, оператор
INSERT INTO Printer_Inc VALUES (15, 3111, 'y', 'laser', 2599);
приведет к ошибке, даже если в таблице нет строки со значением в поле code, равным 15. Поэтому для вставки строки в таблицу просто не будем указывать это поле точно так же, как и в случае использования значения по умолчанию, т.е.
В результате выполнения этого оператора в таблицу Printer_Inc будет вставлена информация о модели 3111 цветного лазерного принтера, стоимость которого равна $2599. В поле code окажется значение, которое только случайно может оказаться равным 15. В большинстве случаев этого оказывается достаточно, т.к. значение автоинкрементируемого поля, как правило, не несет никакой информации; главное, чтобы оно было уникальным.
Однако бывают случаи, когда требуется подставить вполне конкретное значение в автоинкрементируемое поле. Например, нужно перенести уже имеющиеся данные во вновь создаваемую структуру; при этом эти данные участвуют в связи "один-ко-многим" со стороны "один". Таким образом, мы не можем допустить тут произвола. С другой стороны, нам не хочется отказываться от автоинкрементируемого поля, т.к. оно упростит обработку данных при последующей эксплуатации базы данных.
Поскольку стандарт языка SQL не предполагает наличия автоинкрементируемых полей, то соответственно не существует и единого подхода. Здесь мы покажем, как это реализуется в MS SQL Server. Оператор
SET IDENTITY_INSERT < имя таблицы > { ON | OFF };
отключает (значение ON) или включает (OFF) использование автоинкремента. Поэтому чтобы вставить строку со значением 15 в поле code, нужно написать
SET IDENTITY_INSERT Printer_Inc ON;
INSERT INTO Printer_Inc(code, model, color, type, price)
VALUES (15, 3111, 'y', 'laser', 2599);
Обратите внимание, что список столбцов в этом случае является обязательным, т.е. мы не можем написать так:
SET IDENTITY_INSERT Printer_Inc ON;
INSERT INTO Printer_Inc
VALUES (15, 3111, 'y', 'laser', 2599);
ни, тем более, так
SET IDENTITY_INSERT Printer_Inc ON;
INSERT INTO Printer_Inc(model, color, type, price)
VALUES (3111, 'y', 'laser', 2599);
В последнем случае в пропущенный столбец code значение не может быть подставлено автоматически, т.к. автоинкрементирование отключено.
Важно отметить, что если значение 15 окажется максимальным в столбце code,то далее нумерация продолжится со значения 16. Естественно, если включить автоинкрементирование: SET IDENTITY_INSERT Printer_Inc OFF.
Наконец, рассмотрим пример вставки данных из таблицы Product в таблицу Product_Inc, сохранив значения в поле code:
SET IDENTITY_INSERT Printer_Inc ON;
INSERT INTO Printer_Inc(code, model,color,type,price)
SELECT * FROM Printer;
По поводу автоинкрементируемых столбцов следует еще сказать следующее. Пусть последнее значение в поле code было равно 16, после чего строка с этим значением была удалена. Какое значение будет в этом столбце после вставки новой строки? Правильно, 17, т.к. последнее значение счетчика сохраняется, несмотря на удаление строки, его содержащей. Поэтому нумерация значений в результате удаления и добавления строк не будет последовательной. Это является еще одной причиной для вставки строки с заданным (пропущенным) значением в автоинкрементируемом столбце.
Оператор UPDATE изменяет имеющиеся данные в таблице. Команда имеет следующий синтаксис
UPDATE <имя таблицы>
SET {имя столбца = {выражение для вычисления значения столбца
| NULL
| DEFAULT},...}
[ {WHERE <предикат>}];
С помощью одного оператора могут быть заданы значения для любого количества столбцов. Однако в одном и том же операторе UPDATE можно вносить изменения в каждый столбец указанной таблицы только один раз. При отсутствии предложения WHERE будут обновлены все строки таблицы.
Если столбец допускает NULL-значение, то его можно указать в явном виде. Кроме того, можно заменить имеющееся значение на значение по умолчанию (DEFAULT) для данного столбца.
Ссылка на "выражение" может относиться к текущим значениям в изменяемой таблице. Например, мы можем уменьшить все цены ПК-блокнотов на 10 процентов с помощью следующего оператора:
UPDATE Laptop SET price=price*0.9
Разрешается также значения одних столбцов присваивать другим столбцам. Пусть, например, требуется заменить жесткие диски менее 10 Гб в ПК-блокнотах. При этом емкость новых дисков должна составлять половину объема RAM, имеющейся в данных устройствах. Эту задачу можно решить следующим образом:
UPDATE Laptop SET hd=ram/2 WHERE hd < 10;
Естественно, типы данных столбцов hd и ram должны быть совместимы. Для приведения типов может использоваться выражение CAST.
Если требуется изменять данные в зависимости от содержимого некоторого столбца, можно воспользоваться выражением CASE. Если, скажем, нужно поставить жесткие диски объемом 20 Гб на ПК-блокноты с памятью менее 128 Мб и 40 гигабайтные - на остальные ПК-блокноты, то можно написать такой запрос:
UPDATE Laptop
SET hd = CASE WHEN ram<128 THEN 20 ELSE 40 END
Для вычисления значений столбцов допускается также использование подзапросов. Например, требуется укомплектовать все ПК-блокноты самыми быстрыми процессорами из имеющихся. Тогда можно написать:
UPDATE Laptop
SET speed = (SELECT MAX(speed) FROM Laptop)
Необходимо сказать несколько слов об автоинкрементируемых столбцах. Если столбец code в таблице Laptop определен как IDENTITY(1,1), то следующий оператор
UPDATE Laptop SET code=5 WHERE code=4
не будет выполнен, т.к. автоикрементируемое поле не допускает обновления, и мы получим соответствующее сообщение об ошибке. Чтобы выполнить все же эту задачу, можно поступить следующим образом. Сначала вставить нужную строку, используя SET IDENTITY_INSERT, после чего удалить старую строку:
SET IDENTITY_INSERT Laptop ON
INSERT INTO Laptop_ID(code, model, speed, ram, hd, price, screen)
SELECT 5, model, speed, ram, hd, price, screen
FROM Laptop_ID WHERE code=4
DELETE FROM Laptop_ID WHERE code=4
Разумеется, другой строки со значением code=5 в таблице быть не должно.
В Transact-SQL оператор UPDATE расширяет стандарт за счет использования необязательного предложения FROM. В этом предложении специфицируется таблица, обеспечивающая критерий для операции обновления. Дополнительную гибкость здесь дает использование операций соединения таблиц. Пример. Пусть требуется указать "No PC" (нет ПК) в столбце type для тех моделей ПК из таблицы Product, для которых нет соответствующих строк в таблице PC. Решение посредством соединения таблиц можно записать так:
UPDATE Product
SET type='No PC'
FROM Product pr LEFT JOIN PC ON pr.model=pc.model
WHERE type='pc' AND pc.model IS NULL
Здесь используется внешнее соединение, в результате чего столбец pc.model для моделей ПК, отсутствующих в таблице PC, будет содержать NULL-значение, что и используется для идентификации подлежащих обновлению строк. Естественно, эта задача имеет решение и в "стандартном" исполнении:
UPDATE Product
SET type='No PC'
WHERE type='pc' and model NOT IN (SELECT model FROM PC)
Оператор DELETE
Оператор DELETE удаляет строки из временных или постоянных базовых таблиц, представлений или курсоров, причем в двух последних случаях действие оператора распространяется на те базовые таблицы, из которых извлекались данные в эти представления или курсоры. Оператор удаления имеет простой синтаксис:
DELETE FROM <имя таблицы > [WHERE <предикат>];
Если предложение WHERE отсутствует, удаляются все строки из таблицы или представления (представление должно быть обновляемым). Более быстро эту операцию (удаление всех строк из таблицы) в Transact-SQL можно также выполнить с помощью команды
TRUNCATE TABLE <имя таблицы>
Однако есть ряд отличий в реализации команды TRUNCATE TABLE по сравнению с использованием оператора DELETE, которые следует иметь в виду:
1. Не журнализируется удаление отдельных строк таблицы. В журнал записывается только освобождение страниц, которые были заняты данными таблицы.
2. Не отрабатывают триггеры, в частности, триггер на удаление.
3. Команда неприменима, если на данную таблицу имеется ссылка по внешнему ключу, и даже если внешний ключ имеет опцию каскадного удаления.
4. Значение счетчика (IDENTITY) сбрасывается в начальное значение. Пример. Требуется удалить из таблицы Laptop все ПК-блокноты с размером экрана менее 12 дюймов.
DELETE FROM Laptop
WHERE screen < 12;
Все блокноты можно удалить с помощью оператора
DELETE FROM Laptop
или
TRUNCATE TABLE Laptop
Transact-SQL расширяет синтаксис оператора DELETE, вводя дополнительное предложение FROM
FROM <источник табличного типа>
При помощи источника табличного типа можно конкретизировать данные, удаляемые из таблицы в первом предложении FROM.
При помощи этого предложения можно выполнять соединения таблиц, что логически заменяет использование подзапросов в предложении WHERE для идентификации удаляемых строк.
Поясним сказанное на примере. Пусть требуется удалить те модели ПК из таблицы Product, для которых нет соответствующих строк в таблице PC.
Используя стандартный синтаксис, эту задачу можно решить следующим запросом:
DELETE FROM Product
WHERE type='pc' AND model NOT IN (SELECT model FROM PC)
Заметим, что предикат type='pc' необходим здесь, чтобы не были удалены также модели принтеров и ПК-блокнотов.
Эту же задачу можно решить с помощью дополнительного предложения FROM следующим образом:
DELETE FROM Product
FROM Product pr LEFT JOIN PC ON pr.model=pc.model
WHERE type='pc' AND pc.model IS NULL
Здесь используется внешнее соединение, в результате чего столбец pc.model для моделей ПК, отсутствующих в таблице PC, будет содержать NULL-значение, что и используется для идентификации подлежащих удалению строк.
Упражнения выполняются на базах данных, описание которых приводится ниже.
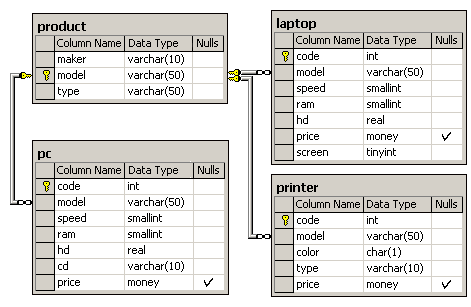
1. Компьютерная фирма
Схема БД состоит из четырех таблиц:
Product(maker, model, type)
PC(code, model, speed, ram, hd, cd, price)
Laptop(code, model, speed, ram, hd, price, screen)
Printer(code, model, color, type, price)
Таблица Product представляет производителя (maker), номер модели (model) и тип ('PC' - ПК, 'Laptop' - ПК-блокнот или 'Printer' - принтер). Предполагается, что номера моделей в таблице Product уникальны для всех производителей и типов продуктов. В таблице PC для каждого ПК, однозначно определяемого уникальным кодом – code, указаны модель – model (внешний ключ к таблице Product), скорость - speed (процессора в мегагерцах), объем памяти - ram (в мегабайтах), размер диска - hd (в гигабайтах), скорость считывающего устройства - cd (например, '4x') и цена - price. Таблица Laptop аналогична таблице РС за исключением того, что вместо скорости CD содержит размер экрана -screen (в дюймах). В таблице Printer для каждой модели принтера указывается, является ли он цветным - color ('y', если цветной), тип принтера - type (лазерный – 'Laser', струйный – 'Jet' или матричный – 'Matrix') и цена - price.
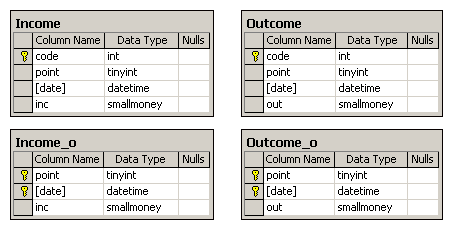
2. Фирма вторсырья
Фирма имеет несколько пунктов приема вторсырья. Каждый пункт получает деньги для их выдачи сдатчикам вторсырья. Сведения о получении денег на пунктах приема записываются в таблицу:
Income_o(point, date, inc)
Первичным ключом является (point, date). При этом в столбец date записывается только дата (без времени), т.е. прием денег (inc) на каждом пункте производится не чаще одного раза в день. Сведения о выдаче денег сдатчикам вторсырья записываются в таблицу:
Outcome_o(point, date, out)
В этой таблице также первичный ключ (point, date) гарантирует отчетность каждого пункта о выданных деньгах (out) не чаще одного раза в день.
В случае, когда приход и расход денег может фиксироваться несколько раз в день, используется другая схема с таблицами, имеющими первичный ключ code:
Income(code, point, date, inc)
Outcome(code, point, date, out)
Здесь также значения столбца date не содержат времени.
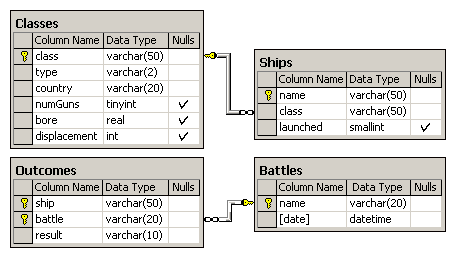
3. Корабли
Рассматривается БД кораблей, участвовавших во второй мировой войне. Имеются следующие отношения:
Classes (class, type, country, numGuns, bore, displacement)
Ships (name, class, launched)
Battles (name, date)
Outcomes (ship, battle, result)
Корабли в «классах» построены по одному и тому же проекту, и классу присваивается либо имя первого корабля, построенного по данному проекту, либо названию класса дается имя проекта, которое не совпадает ни с одним из кораблей в БД. Корабль, давший название классу, называется головным.
Отношение Classes содержит имя класса, тип (bb для боевого (линейного) корабля или bc для боевого крейсера), страну, в которой построен корабль, число главных орудий, калибр орудий (диаметр ствола орудия в дюймах) и водоизмещение ( вес в тоннах). В отношении Ships записаны название корабля, имя его класса и год спуска на воду. В отношение Battles включены название и дата битвы, в которой участвовали корабли, а в отношении Outcomes – результат участия данного корабля в битве (потоплен-sunk, поврежден - damaged или невредим - OK).
Замечания. 1) В отношение Outcomes могут входить корабли, отсутствующие в отношении Ships. 2) Потопленный корабль в последующих битвах участия не принимает.
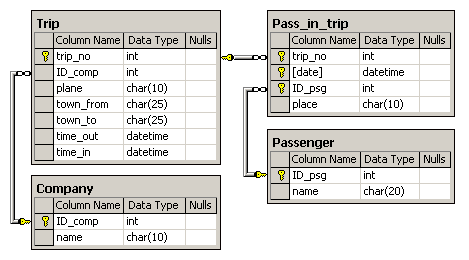
4. Аэрофлот
Схема БД состоит из четырех отношений:
Company (ID_comp, name)
Trip(trip_no, ID_comp, plane, town_from, town_to, time_out, time_in)
Passenger(ID_psg, name)
Pass_in_trip(trip_no, date, ID_psg, place)
Таблица Company содержит идентификатор и название компании, осуществляющей перевозку пассажиров. Таблица Trip содержит информацию о рейсах: номер рейса, идентификатор компании, тип самолета, город отправления, город прибытия, время отправления и время прибытия. Таблица Passenger содержит идентификатор и имя пассажира. Таблица Pass_in_trip содержит информацию о полетах: номер рейса, дата вылета (день), идентификатор пассажира и место, на котором он сидел во время полета. При этом следует иметь в виду, что
- рейсы выполняются ежедневно, а длительность полета любого рейса менее суток; town_from <> town_to;
- время и дата учитывается относительно одного часового пояса;
- время отправления и прибытия указывается с точностью до минуты;
- среди пассажиров могут быть однофамильцы (одинаковые значения поля name, например, Bruce Willis);
- номер места в салоне – это число с буквой; число определяет номер ряда, буква (a – d) – место в ряду слева направо в алфавитном порядке;
- связи и ограничения показаны на схеме данных.
5. Окраска
Схема базы данных состоит из трех отношений:
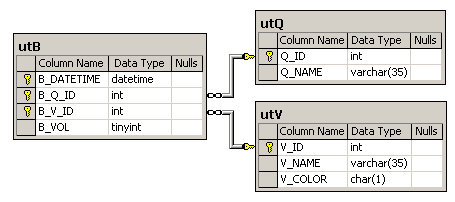
utQ (Q_ID int, Q_NAME varchar(35)); utV (V_ID int, V_NAME varchar(35), V_COLOR char(1)); utB (B_Q_ID int, B_V_ID int, B_VOL tinyint, B_DATETIME datetime).
Таблица utQ содержит идентификатор и название квадрата, цвет которого первоначально черный.
Таблица utV содержит идентификатор, название и цвет баллончика с краской.
Таблица utB содержит информацию об окраске квадрата баллончиком: идентификатор квадрата, идентификатор баллончика, количество краски и время окраски.
При этом следует иметь в виду, что:
- баллончики с краской могут быть трех цветов - красный V_COLOR='R', зеленый V_COLOR='G', голубой V_COLOR='B' (латинские буквы).
- объем баллончика равен 255 и первоначально он полный;
- цвет квадрата определяется по правилу RGB, т.е. R=0,G=0,B=0 - черный, R=255, G=255, B=255 - белый;
- запись в таблице закрасок utB уменьшает количество краски в баллончике на величину B_VOL и соответственно увеличивает количество краски в квадрате на эту же величину;
- значение 0 < B_VOL <= 255;
- количество краски одного цвета в квадрате не превышает 255, а количество краски в баллончике не может быть меньше нуля;
- время окраски B_DATETIME дано с точностью до секунды, т.е. не содержит миллисекунд.
Приложение 2. Список упражнений (SELECT)
Ниже приводится список рейтинговых упражнений первого этапа, необязательных к решению с точки зрения сертификации и продвижения по этапам.
Указывается номер, под которым упражнение фигурирует в заданиях, номер базы данных, к которой относится упражнение, и уровень сложности.
Номер
База
Уровень
Упражнение
-1
5
1
Методом наименьших квадратов найти линейную зависимость мгновенного расхода краски от времени: V = at + b, где V - расход краски; t - время в секундах, отсчитываемое от первой окраски (t = 0). Вывод: a с 8-ю знаками после десятичной точки; b - с 2-мя знаками после десятичной точки.
-2
3
2
Для каждой страны определить год, когда на воду было спущено максимальное количество ее кораблей. В случае, если окажется несколько таких лет, взять минимальный из них. Вывод: страна, количество кораблей, год
-3
5
2
На планете Торус 6x4 живут торусианцы трёх цветов (красные, зелёные и синие). Первые 24 квадрата таблицы utQ, отсортированные по Q_ID - страны планеты: Т00 - первый квадрат Т03 - четвёртый квадрат Т10 - пятый квадрат T53 - двадцать четвертый квадрат Количество краски на квадрате - численность торусианцев соответствующего цвета в стране (R, G, B). В день рождения Меркадота все торусианцы в каждой стране разбиваются на группы - 8 групп каждого цвета; численность каждой группы определяется как R/8, G/8, B/8 - и направляются в 8 соседних стран (по одной группе каждого цвета на страну). Не попавшие в группы торусианцы в количестве R%8, G%8, B%8 остаются дома. Найти количество торусианцев каждого цвета в каждой стране в этот знаменательный день. Вывести на карте Меркадота для страны "Т00" количество торусианцев каждого цвета в странах Txy (x - номер строки, y - номер столбца) в формате "Txy - cccR cccG cccB", где Txy - название страны, ccc - количество с ведущими нулями.
-4
5
2
Найти квадраты, время между первой и последней окраской которых превышает среднее время по всем окрашенным квадратам. Вывести название квадрата и наибольшее время между двумя его последовательными окрасками в секундах.
-5
3
1
В таблице Battles кроме крупных битв с участием многих кораблей содержатся также записи, начинающиеся с символа #, содержащие информацию о мелких стычках. Связанные инциденты объединены в группы от 1 до 6 стычек. Формат наименования для таких записей следующий: - после # идет код группы инцидентов (не содержит цифр, может отсутствовать) - далее идет номер группы в журнале регистрации (целое число, присутствует обязательно) - далее указывается номер инцидента внутри группы. Инциденты могут нумероваться арабскими и римскими цифрами, буквами латинского алфавита с различными разделителями, например a,b,c... /1,/2,/3... .1,.2,.3... i,ii,iii... и т.п. Нумерация едина для всей группы и не содержит пропусков. Первая или единственная стычка в группе может не иметь дополнительного номера. Требуется вывести список стычек, отсортированный по коду группы, номеру группы, дополнительному номеру. Вывод: наименование стычки, номер по порядку (начиная с 1)
-6
4
2
Опираясь на утверждение, что одна секунда полета каждого пассажира приносит перевозчику 1 цент (0.01$) дохода, провести АВС-анализ привлекательности пассажиров вне зависимости от перевозчика. В основе метода лежит принцип Парето - 20% всех товаров дают 80% оборота. При выполнении анализа пассажиры делятся на 3 категории по степени их ценности: А, В и С. Порядок проведения анализа: 1. Рассчитываем долю дохода пассажира от общей суммы дохода, приносимой всеми пассажирами, с накопительным итогом. Доля с накопительным итогом высчитывается путём прибавления доли конкретного пассажира к сумме долей пассажиров с не меньшей долей дохода (при одинаковой доле дохода меньший накопительный итог будет у пассажира, имя которого идет раньше в алфавитном порядке). 2. Выделяем категории А,В и С. Категория А - округленная до двух десятичных знаков накопительная доля с 0,00% по 80,00% включительно, категория В - с 80,01% до 95,00%, категория С - с 95,01% до 100%. Вывод: имя пассажира, сумма прибыли в долларах, доля с накопительным итогом в процентах (точность - 2 знака после запятой), категория (А, В или С - буквы латинские)
-7
1
1
В таблице Product найти модели, у которых первый символ представляет собой четную цифру, а последний - нечетную. При этом первый символ должен быть меньше последнего. Вывод: номер модели, тип модели, произведение первой и последней цифр в номере модели
-8
2
2
Фирма открывает новые пункты по приему вторсырья. При открытии, каждому из них были выданы "подъемные" в размере 20 т.р. Каждому из пунктов была поставлена задача об увеличении первоначального капитала до 150%, с отчетностью - один раз в день. Используя одну только таблицу Outcome_o и при условии, что пункты работают с двойной накруткой, то есть на каждый выплаченный сдатчику рубль они получают доход 2 рубля, найти: - Для пунктов, справившихся с заданием, определить дату его выполнения и сумму денежных средств, полученных сверх плана на эту дату; - Для пунктов, которые не справились с заданием, определить на последнюю отчетную дату сумму денежных средств, недостающих до его выполнения. Вывод: пункт, дата выполнения (или последний день), сумма сверх плана (или недостающую сумму до плана).
-9
3
1
В таблице Outcomes один тот же корабль может встречаться неоднократно (принимал участие в нескольких сражениях). Требуется найти корабли, имена которых различаются только регистром букв, например, "Duke of York" и "duke Of york". Вывод: имя корабля (любой из вариантов), число различных вариантов написания имени данного корабля в таблице.
-10
4
1
Отобразить карту полётов на статических картах Google. На карте вывести только уникальные направления полётов таким образом, что название первого города раньше по алфавиту, чем название второго города. Например, если есть рейс из Рима в Берлин, но нет из Берлина в Рим, то вывести направление Берлин-Рим. Или если есть оба рейса, из Милана в Мадрид и из Мадрида в Милан, то вывести только направление Мадрид-Милан. Полученные направления вывести в алфавитном порядке их городов. Для каждого города вывести метки с первой буквой его названия. В итоге должна получиться строка следующего вида (без переводов строк): <img src="http://maps.googleapis.com/maps/api/staticmap ?path=weight:3|Aaa|Bbb &path=weight:3|Aaa|Ccc &path=weight:3|Bbb|Ccc &markers=label:A|Aaa &markers=label:B|Bbb &markers=label:C|Ccc &size=512x512&sensor=false"> где <img src="http://maps.googleapis.com/maps/api/staticmap - это указание использовать статические карты Google; ?path=weight:3|Aaa|Bbb - первое направление, из пункта Aaa в Bbb, с толщиной линии 3; &path=weight:3|... - все следующие направления; &markers=label:A|Aaa - метка (A) города Aaa; &size=512x512 - указание размера карты 512x512; &sensor=false"> - обязательный параметр.
-11
3
1
Для каждого корабля из таблицы Ships вывести его название в base64 (wikipedia). Вывод: name, base64name.
-12
4
1
В аэропорту математик Иванов развлекал себя подсчетом факториала от номера рейса. Для каждого рейса в Trip определите на сколько нулей оканчивается вычисленное Ивановым число. Замечание: номер рейса содержит не более 4 цифр. Вывод: trip_no, число нулей.
-13
4
1
Определить количество перевезенных пассажиров за каждый календарный день (по дате вылета) первого полугодия 2003 года, начиная от даты первого рейса и заканчивая датой последнего рейса в этом полугодии. Полугодием считать интервал с (01.01.03 по 30.06.03). Вывести дату, количество пассажиров.
-14
3
1
Вывести названия только тех классов, у которых каждый корабль имеет такое имя, что любой его символ встречается в названии какого-либо класса. Замечание: регистр букв при сравнении не учитывается.
-15
5
2
На плоском песчаном пляже в координатах B_Q_ID, B_V_ID установлены круглые пляжные зонтики радиуса B_VOL. Зонтики параллельны песку, солнце в зените. Каждое значение B_DATETIME - отдельная задача. Найти площадь тени для каждого B_DATETIME. Вывод: B_DATETIME, площадь тени округлённая до целых.
-16
2
1
Найти такие пункты приема, которые имеют в таблице Outcome записи на каждый рабочий день в течение некоторой недели (календарные дни, исключая субботу и воскресенье). Вывод: номер пункта, дата понедельника полной рабочей недели в формате "YYYY-MM-DD", суммарное значение out за эту рабочую неделю.